Data en operationalisering
We behandelen methoden en analyse in dit Handboek los van elkaar, maar in de praktijk zul je hier tegelijkertijd over moeten nadenken. Je keuze zal namelijk afhangen van het type data waar je naar op zoek bent en wat je onderzoekseenheden zijn.
Wat is ‘data’ nu eigenlijk precies? In onderzoek worden informatie of gegevens tot data gemaakt door onderzoekers, zodat ze deze kunnen analyseren om tot antwoorden op hun onderzoeksvragen te komen. Data is dus relatief aan je onderzoeksvragen en je structuur. Er bestaan veel typen data (cijfers, tekst, beeld, geluid) en deze zullen in methoden van analyse variëren. Je kunt data transformeren naar een ander type door bijvoorbeeld te aggregeren, samen te vatten, uit te schrijven of te beschrijven. Daarnaast is het vaak handig om metadata over je data op papier te zetten. Dit is data over data: een beschrijving van hoe je data eruitziet en hoe deze is gestructureerd.
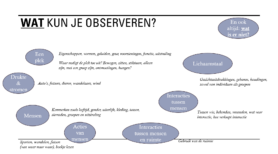
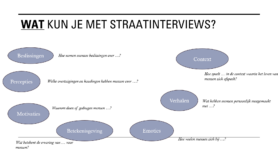
Observaties over het nachtleven en de bijbehorende economie kunnen tot verschillende data worden gemaakt afhankelijk van hoe onderzoekers hiermee omgaan. In Schwanen, van Aalst, Brands & Timon (2012, pp. 2068-9), bijvoorbeeld, gebruikten de onderzoekers gestructureerde observaties in stadscentra van Groningen, Utrecht en Rotterdam op donderdag t/m zaterdagnacht van 10 uur ’s avonds tot 5 uur ’s ochtends. De observaties werden gedaan op vier verschillende plekken en namen steeds 10 minuten in beslag. Op deze momenten telden de onderzoekers het aantal bezoekers dat ze zagen, opgedeeld per gender, de grootte van groepen in de publieke ruimte, het aantal politieagenten en hun uitrusting, het aantal private veiligheidsmedewerkers, handhavers, gevallen van wanorde, het weer, en ook verschillende geuren (voedsel, urine). Ze namen zichzelf op door een verhalend verslag in te spreken over de gebeurtenissen en algehele sfeer op dat moment. De onderzoekers hebben nu dus verschillende typen data, over geur, geluid, maar ook cijfers. De verschillende gegevens werden gedigitaliseerd, gecategoriseerd en de opnames werden getranscribeerd. Cijfers en composities van bezoekers werden gecombineerd en vergeleken om tot een lage en hoge schatting te komen van het aantal bezoekers per gender en tijdsinterval. De verschillende typen data geven de mogelijkheid om verschillende typen analyses uit te voeren, een mixed-methods benadering: kwalitatief en kwantitatief. Op basis hiervan kunnen de onderzoekers bijvoorbeeld een tabel maken waarin ze in cijfers het aantal bezoekers per stad en locatie weergeven (zie p. 2073) en een regressieanalyse uitvoeren, bv voor het aandeel van vrouwen in de nachtelijke economie (zie p. 2079). In combinatie met interviews, het volgen van bezoekers of politieagenten, of het bekijken van CCTV-beelden, waren ook kwalitatieve analyses op deze data mogelijk. Schwanen, T., van Aalst, I., Brands, J. & Timan, T. (2012). Rhythms of the night: spatiotemporal inequalities in the nighttime economy. Environment and Planning A. 44, pp. 2064-2085. Doi:10.1068/a44494
Primaire data / zelf geconstrueerde data – ‘Primaire data’ of zelf geconstrueerde data zijn de gegevens die we zelf verzamelen door bijvoorbeeld interviews, enquêtes, focus groepen en observaties. De meeste methoden kun je fysiek, telefonisch, per post, maar ook virtueel/online doen. De uitgeschreven transcripten van de interviews en focus groepen, de ingevulde enquêtes en notities van de observaties vormen samen de primaire data voor het onderzoek. Salmons, J. (2021). Doing qualitative research online. London : SAGE Publications Ltd.
Secundaire data / gepreconstrueerde data – ‘Secundaire data’, ‘gepreconstrueerde data’ of ‘extant data’ zijn gegevens die al eerder door anderen zijn verzameld voor hun eigen doeleinden. Deze gegevens kunnen we analyseren voor onze eigen doeleinden middels een secundaire data-analyse. Hier kan het gaan om officiële statistieken, zoals van het CBS of Eurostat, maar ook politieke documenten, Tweede Kamerverslagen en onderzoeksrapporten.
Als je van officiële bronnen gebruik gaat maken, zoals rapporten van de overheid, bekijk deze met een kritisch blik. Vraag jezelf af waarom deze informatie bijeengebracht is, met welk overheidsbeleid het te maken heeft en of beleidskeuzes wellicht de dataverzameling hebben beïnvloed. Kijk ook goed naar welke “stemmen” wel en niet in het rapport voorkomen, en welke retorische stijl is gebruikt. In het geval van officiële statistieken, ga je na welke categorieën zijn gebruikt, waarom en of andere categorieën ook gebruikt hadden kunnen worden. Welke steekproef en survey techniek is gebruikt in de dataverzameling? Zie ook Open Datasets en de Handleiding Wegwijs in Open Data (2024).
Andere secundaire/gepreconstrueerde data zullen van niet-officiële bronnen komen. Denk hierbij aan onderzoeksrapporten van bekendere en minder bekende organisaties, intern materiaal van organisaties, documentaires, reclame, persoonlijke documenten of kaarten. Je kunt ook representatie bronnen (“imaginative sources”) gebruiken. Denk hierbij aan literatuur, reisverhalen, schilderijen, fotografie, film, architectuur, muziek, theater, computer spellen en virtual reality.
Tekst, visualisaties, geluid, cijfers – Een andere manier om typen data van elkaar te onderscheiden is de vorm waarin je met ze werkt. Gaat het om geschreven tekst, visuele data, geluid of cijfers? Afhankelijk van het doel van je onderzoek en je onderzoeksvraag, zal je verschillende soorten data nodig hebben. Ook heeft het type data dat je gebruikt invloed op welke analyses je kunt uitvoeren.
- Bij tekst kun je denken aan: Interview transcripten (verbatim), veldnotities, veldobservaties, wetten en regelgeving, Officiële staatsdocumenten (Tweede kamer-verslagen, rapporten, studies, onderzoeken, PBL, CBS, beleidsdocumenten), onderzoeksrapporten, intern materiaal van organisaties (memo’s, communicatie), reclame en promotiemateriaal, persoonlijke documenten (dagboeken), nieuwsartikelen, reisverhalen en literatuur.
- Visuele data: Foto’s, video’s, tekeningen, film/documentaire, architectuur, computerspellen, virtual reality, schilderijen, reclame en kaarten.
- Geluid: Radiofragmenten, muziek, reclame en opnames van geluid in de publieke ruimte.
- Cijfers: Open datasets/statistieken, eigen enquête data en observaties (turven/tellen).
Zowel in kwantitatief als kwalitatief onderzoek operationaliseer je je belangrijkste concepten naar meetbare en/of waarneembare begrippen. Concepten zijn vaak abstracte begrippen en niet direct te observeren of te bevragen. Er moet dus een vertaalslag worden gemaakt van theorie naar praktijk. Dit proces heet operationaliseren. Je beschrijft voor elke variabele in het conceptueel model hoe je daarvan de data gaat verzamelen. Daarbij zijn twee dingen van belang:
- Verantwoording van je keuzes vanuit de literatuur: hoe maak je concepten meetbaar en/of waarneembaar? Hoe is dat in andere onderzoeken gedaan? Beargumenteer op basis van de literatuur waarom je een construct op een bepaalde manier meetbaar/waarneembaar maakt.
- Welke gegevens heb je nodig om jouw onderzoeksvragen te beantwoorden en/of jouw hypothesen te kunnen toetsen? Je moet hierbij dus al vooruitkijken naar de analyse van je data: Welke analyses ben je van plan uit te voeren? Welke toetsen? Wat voor soort data heb je daarvoor nodig?